
今天的話,我們用更貼近TF的語言來做DNN,Data的部分使用TF.Keras api裡面的資料來做使用。TF.Keras dataset包含有 CIFAR 10、100 (彩色圖片) 、 IMDB評論情感分析、路透社新聞分類、MNIST手寫辨識以及這次使用的Fashion MNIST。
Fashion MNIST
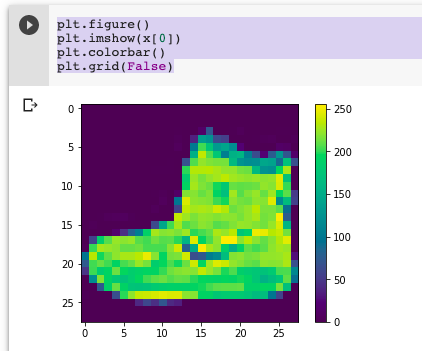
Fashion MNIST是一個涵蓋10個種類的服飾正面灰階圖片 (28*28),主要為Zalando所release的dataset,很適合大家一開始用來嘗試各式各樣的model。而TF.keras.dataset的api已經整理很乾淨。因此,若使用的都可以直接call api,就可以下載dataset到local做使用。
(x,y),(x_test,y_test) = datasets.fashion_mnist.load_data()
print(x.shape,y.shape)
#Output: x -> (60000, 28, 28) y -> (60000,)
接下來稍微看一下圖片長什麼樣子
plt.figure()
plt.imshow(x[0])
plt.colorbar()
plt.grid(False)
在TF 2.0,主要default mode為eager executuin。因此,主要在讀取資料或者資料上的操作會使用 tf.data 的api,也是TF 2.0重要的一個feature。透過tf.data,會更清楚、方便去描述資料流的處理過程 。在讀檔案的話,若您的data先讀好了,就可以使用像是tf.data.Dataset.from_tensors()或者 tf.data.Dataset.from_tensor_slices(),若還沒有的話就可以使用tf.data.TFRecordDataset()去讀File。
data = tf.data.Dataset.from_tensor_slices((x,y))
若是針對資料處理的話(Transformation),常見的方法就有map、shuffle、batch等等。以下就會用這個dataset來做簡單的舉例。以map來說,就是將function套用到每一個dataset裡面的element。shuffle的話就是打散整個dataset,最後在設定你一個batch要有多少筆資料。
def feature_scale(x,y):
x = tf.cast(x,dtype=tf.float32)/255.
y = tf.cast(y,dtype=tf.int32)
return x,y
data = data.map(feature_scale).shuffle(10000).batch(128)
建立好Dataset之後,就是將資料迭代化,這是tf.data api的特色。建立Dataset -> 資料迭代化 -> 放進Model
data_iter = iter(data)
samples = next(data_iter)
print(samples[0].shape,samples[1].shape)

接下來就可以跟上一篇一樣定義Model,以及想使用的optimizer
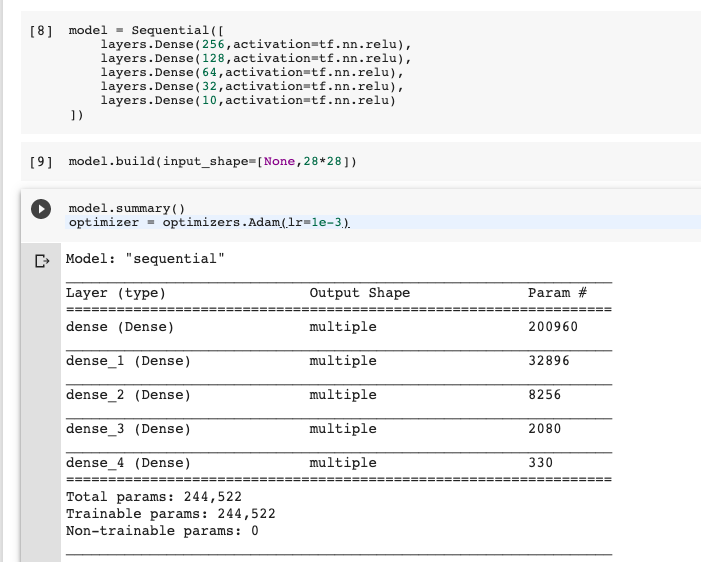
model = Sequential([
layers.Dense(256,activation=tf.nn.relu),
layers.Dense(128,activation=tf.nn.relu),
layers.Dense(64,activation=tf.nn.relu),
layers.Dense(32,activation=tf.nn.relu),
layers.Dense(10,activation=tf.nn.relu)
])
model.build(input_shape=[None,28*28])
model.summary()
optimizer = optimizers.Adam(lr=1e-3)
接下來就是寫您要train的次數,每train一次都要跑完所有batch。這邊的部分會使用TF 2.0主要使用自動計算gradient的方法,這樣在客製化loss function或者想要改變其他計算的方式的時候也比較容易。(像最近聽聞附近的有些朋友有嘗試使用focal loss來解決資料不平衡的問題)。最後計算出loss後,會使用tape.gradient將loss傳入計算gradient,最後使用前面所設的optimizer來更新weight。
with tf.GradientTape() as tape:
logits = model(x)
y_one_hot = tf.one_hot(y,depth=10)
loss = tf.losses.categorical_crossentropy(y_one_hot,logits,from_logits=True)
loss = tf.reduce_mean(loss)
grads = tape.gradient(loss,model.trainable_variables)
optimizer.apply_gradients(zip(grads,model.trainable_variables))
最後test的部分跟train的寫法差不多,主要差在使用tf.argmax跟tf.equal去計算差異。
x = tf.reshape(x,[-1,28*28])
gd = model(x)
prob = tf.nn.softmax(gd,axis=1)
pred = tf.argmax(prob,axis=1)
pred = tf.cast(pred,dtype=tf.int32)
correct = tf.equal(pred,y)
result = tf.reduce_sum(tf.cast(correct,dtype=tf.int32))
total_loss += int(result)
今天將DNN run在影像辨識上,並稍微用更貼近TF2.0的語言來跑model。TF2.0上更強貼整個data pipeline。接下來,在進入Recommendation System、CNN、RNN等等模型前,還是會先討論一下Overfit、TF.keras api以及TensorBoard的部分,感謝大家漫長的閱讀!
TF_image binary classification

 iThome鐵人賽
iThome鐵人賽